Day 30: Summing up
On Day 29, we conducted our out-of-sample test on the four strategies and found that the adjusted strategy came out on top. We made this conclusion after ranking a cross section of the following metrics: cumulative return, Sharpe Ratio, and max drawdown. If we wanted to commit capital, there would be a lot more work to do. But with the bulk of the backtesting over, it’s time to sum up what we learned.
We started this series for a number of reasons, foremost being that most backtests we’ve seen tend to hide the meat of the work. One gets a thesis, some methodology, and results. That is all well and good for experienced quants and/or folks more concerned with results than process. But it doesn’t do much for the novice or non-professional. We understand many folks don’t want to know how the sausage is made. That is, until they find out it’s full of nitrates and preservatives. Our view is that details are important if you’re risking your own capital. So we wanted to highlight some of the questions one might need to answer when building, backtesting, and analyzing a strategy that was not presented for the sake of content marketing.1
Another reason for the series was to refine our own thinking about backtesting approaches explicitly. There’s a big difference between making a choice about a certain parameter in one’s head and having to explain it clearly in writing. Having to write clearly requires one to think clearly. So what did we learn? What was a surprise?
Sometimes even simple strategies can be improved by adding targeted refinements. Our backtest used momentum as the main driver for returns, as discussed frequently in the academic literature. This was not a ground breaking approach. But what surprised us was how much adding an error correction term improved results. As we discussed, this approach was somewhat hacky, but did have a basis in machine learning practices. We certainly believe adding an error correction term is an interesting refinement that could be tested on any strategy.
Once there’s more than one benchmark, another model or process is necessary to adjudicate the results. It is common to use a bunch of metrics to decide on whether a strategy is viable once it has passed muster. Once we tried to do that with the strategies we analyzed, we found our process to be decidedly ungrounded and subjective. We glossed over this aspect of the analysis for the sake of space and time, using a simple ranking system. That might be fine for a blog post. But it was an on-the-fly choice. We should really have had a logical, if not rigorous, process in place to handle the decision. We’re not sure if a meta-model is appropriate – without having a lot idiosyncratic backtests to inform that model – but an overarching system based on a logical hypothesis would have been better.
Simulation reveals useful comparisons, but it should have a well-defined place in the overall analysis. We were surprised by how poorly most of the strategies performed in simulation. That may have been a fault of how we set up the simulation, but we didn’t examine that in detail. Perhaps we should have employed more simulations or refined the simulation process itself. Even though the simulations didn’t produce a high likelihood of success, we were hesitant to give them veto power on strategy viability. Maybe that was a bias on our part. But they’re simulations after all. Still, it begs the question, should simulations function as a gate you open only if the strategy passes the test? What should the passing score be? Or should the outcome of a simulation be treated as a separate metric to be compared with all the other metrics in the final decision for the strategy?
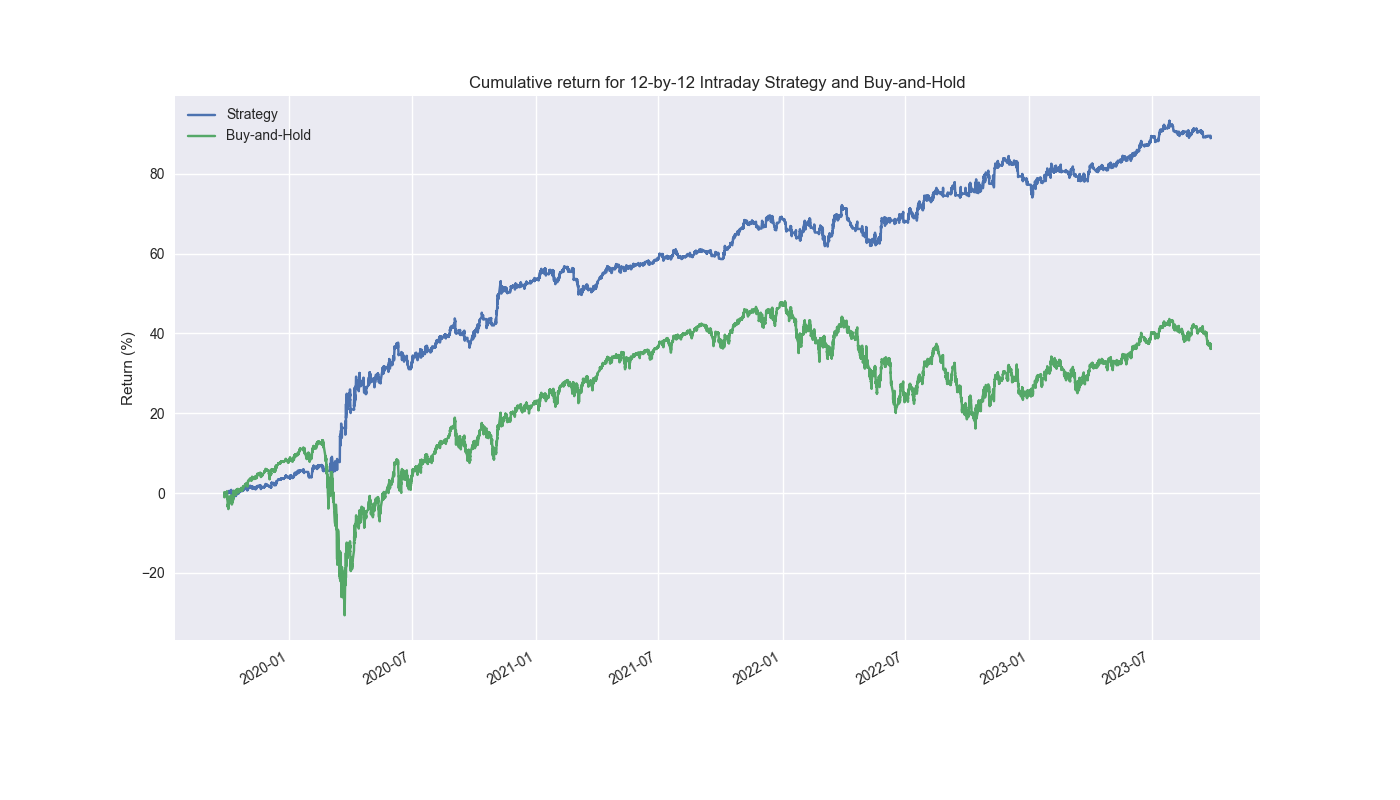
We’ll leave the above questions open for now. While we’re not done with backtesting by any means, we’d like to explore other important components of the investing process in our forthcoming posts. Indeed, while we used weekly returns vs. the monthly returns found in the literature, it would be interesting to drill down further into daily or even intra-day returns. Here’s a teaser. We use the 12-by-12 lookback/look forward method to test a strategy on 5-minute intraday bars, successively building models trained on 2.5 days of data and forecasting the next half day.
In the end, there are no lack of topics to explore even without navel gazing, which we hope to avoid at all costs. But we don’t want to follow only our own interests. We’d like to hear from our readers. What would you like to read? Long series like #30daysofbacktesting or one-off posts? Single strategy backtests or multiple strategies with portfolio optimization? Quantitative trading or fundamental investing? Macro or micro? Please let us know by reaching out to content at optionstocksmachines dot com. Until next time. Stay tuned!
Code below.
# Built using Python 3.10.19 and a virtual environment
# Load packages
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
import statsmodels.api as sm
import matplotlib.pyplot as plt
import yfinance as yf
plt.style.use('seaborn-v0_8')
plt.rcParams['figure.figsize'] = (14,8)
# Get data
# Unfortunately, open-source, intraday data is hard to come by. The data we use requires a subscription and API key, so we don't show how to extract it. Once we figure out how to find free data, we'll write a post on that. Apologies
df = pd.read_csv("spy_2019-09-27_2024-09-26_5Min.csv").drop("Unnamed: 0", axis=1)
df = df[['date', 'open', 'high', 'low', 'close']]
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
df.index = df.index.tz_convert('US/Eastern')
df = df.between_time("09:30", "16:00")
# Process data
forward = 12
back = 12
df_out = df[['close']].copy()
df_out['ret_back'] = np.log(df_out['close']/df_out['close'].shift(back))
df_out['ret_for'] = np.log(df_out['close'].shift(-forward)/df_out['close'])
df_out = df_out.dropna()
# Run walk-forward model
# Train on 2.5 days of 5 minute data
train_pd = int(78*5*.5)
# Forecast on half a day
test_pd = int(78*.5)
tot_pd = train_pd + test_pd
# Create train set
df_trade = df_out.loc[:"2023-09-26"]
# Run algorithm
trade_pred = []
for i in range(tot_pd, len(df_trade)+1, test_pd):
train_df = df_trade.iloc[i-tot_pd:i-test_pd, 1:]
test_df = df_trade.iloc[i-test_pd:i, 1:]
# Ensure 'ret_back' is 2D by selecting it as a DataFrame, not a Series
X_train = sm.add_constant(train_df[['ret_back']])
if test_df.shape[0] > 1:
X_test = sm.add_constant(test_df[['ret_back']])
else:
X_test = sm.add_constant(test_df[['ret_back']], has_constant='add')
# Fit the model
mod_run = sm.OLS(train_df['ret_for'], X_train).fit()
# Predict using the test data
mod_pred = mod_run.predict(X_test).values
trade_pred.extend(mod_pred)
# Adjust trade dataframe for clipped end data
df_trade_1 = df_trade.copy()
df_trade_1 = df_trade_1[:X_test.index[-1]]
# Add predictions and returns
df_trade_1['pred'] = np.concatenate((np.repeat(np.nan, train_pd), np.array(trade_pred)))
df_trade_1['ret'] = np.log(df_trade_1['close']/df_trade_1['close'].shift(1))
# Generate signals
df_trade_1['signal'] = np.where(df_trade_1['pred'] == np.nan, np.nan, np.where(df_trade_1['pred'] > 0, 1, 0))
df_trade_1['signal_sh'] = np.where(df_trade_1['pred'] == np.nan, np.nan, np.where(df_trade_1['pred'] >= 0, 1, -1))
# Generate strategy returns
df_trade_1['strat_ret'] = df_trade_1['signal'].shift(1) * df_trade_1['ret']
df_trade_1['strat_ret_sh'] = df_trade_1['signal_sh'].shift(1) * df_trade_1['ret']
# Plot cumulative returns
(df_trade_1[['strat_ret', 'ret']].cumsum()*100).plot()
plt.ylabel("Return (%)")
plt.xlabel("")
plt.legend(['Strategy', 'Buy-and-Hold'])
plt.title('Cumulative return for 12-by-12 Intraday Strategy and Buy-and-Hold')
plt.show()The irony that
#30daysofbacktestingmight be considered content marketing is not lost on us. But in this case, we’re referring to those endless posts of amazing results that are cherry-picked to entice the reader to BUY THE COURSE that will teach them how to generate 5-figure annual cash returns in the comfort of their own home!↩︎